필요한 것은 아니었지만 각 사이트의 메인화면을 스크린샷으로 찍어두는 프로그램이 있었으면 하는 상황이 있었었다.
물론 결국 필요해지진 않았지만 Selenium을 이용한 스크린샷을 찍는 방법을 정리한 다면 나중에 쓸 일이 있을 것 같아 정리를 하기로 하였다.
selenium으로 스크린샷을 저장하는 방법은 매우 간단하다.
# driver 기본 설정 후 driver를 반환
driver = open_driver()
driver.get(url)
driver.save_screenshot(path)
driver의 save_screenshot()을 사용하면 끝이 난다.
from selenium import webdriver
def open_driver():
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--ignore-certificate-errors')
options.add_argument('--ignore-ssl-errors')
driver = webdriver.Chrome('chromedriver 지정', options=options)
driver.delete_all_cookies()
driver.implicitly_wait(10)
driver.set_page_load_timeout(10)
driver.set_script_timeout(10)
driver.maximize_window()
return driver
def main():
driver = open_driver()
try:
driver.get('https://www.daum.net')
driver.save_screenshot('./Daum.png')
except Exception as e:
log.error('selenium screenshot error.')
finally:
driver.quit()
if __name__ == '__main__':
main()
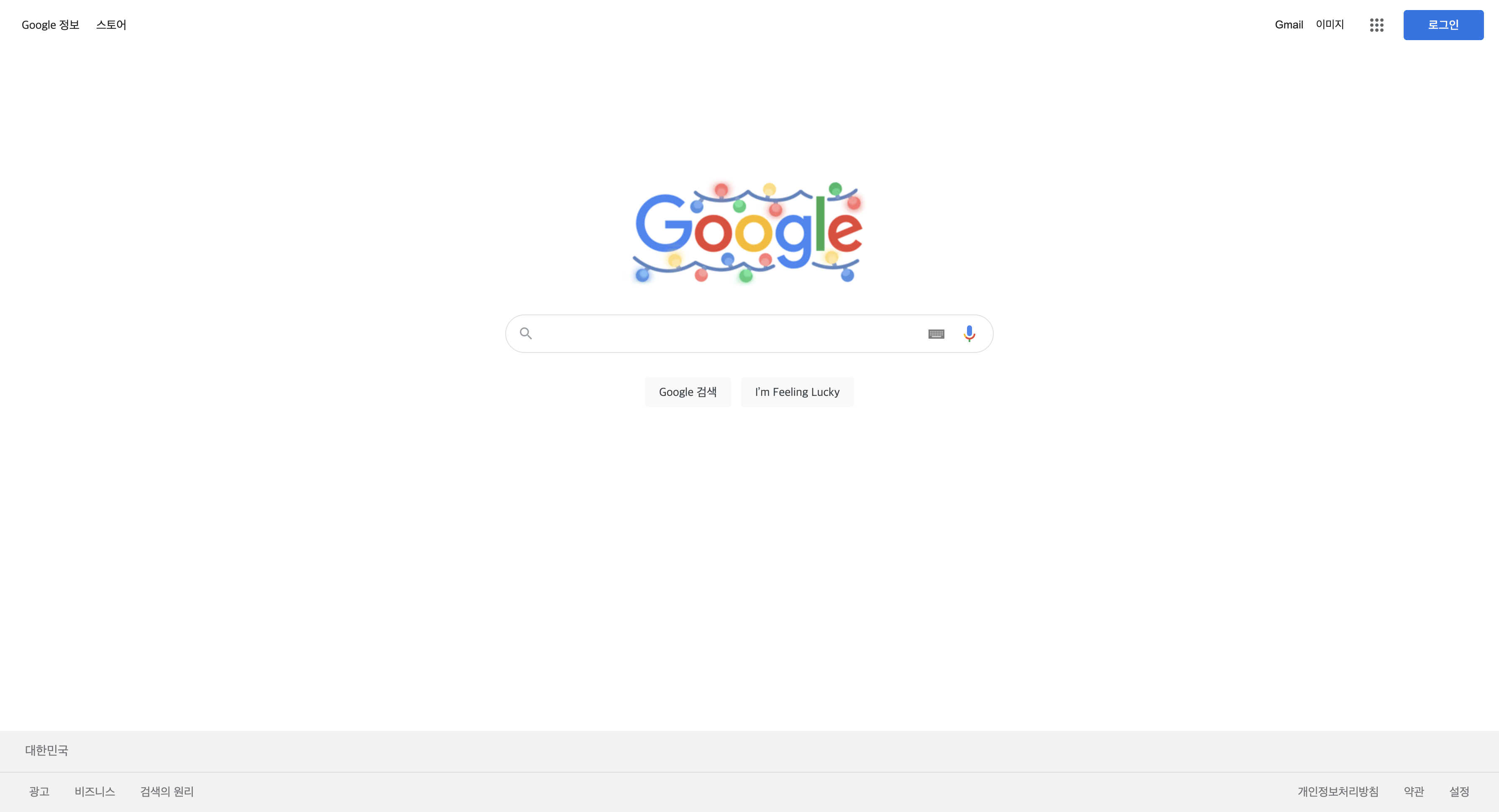
위의 코드를 돌려보면 다음의 메인화면이 Daum.png라는 이름으로 저장된다.

또는 element를 지정해 스크린샷을 저장할 수도 있는데
driver.get('https://www.daum.net')
el = driver.find_element(By.TAG_NAME, 'body')
el.screenshot('./Daum.png')
위처럼 element를 지정하고 해당 element에서 screentshot()을 호출해주면

이렇게 스크린샷이 저장되게 된다.
driver의 save_screenshot()과는 다르게 스크롤바의 모습이 스크린샷으로 찍히지 않는다.
body 태그가 아닌 다른 요소를 지정해서 저장하면
driver.get('https://www.daum.net')
el = driver.find_element(By.XPATH, '//div[@id="inner_login"]/a[@class="link_login link_kakaoid"]')
el.screenshot('./Daum.png')
해당 요소만 저장되는 것을 확인할 수 있다.
이렇게 스크린샷을 찍는 방법을 활용해서 여러 사이트의 주소를 적은 txt 파일을 읽어 해당 사이트들의 메인을 찍는 코드를 다음과 같이 작성했다.
from selenium import webdriver
from log import log
def open_driver():
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--ignore-certificate-errors')
options.add_argument('--ignore-ssl-errors')
driver = webdriver.Chrome('chromedriver 지정', options=options)
driver.delete_all_cookies()
driver.implicitly_wait(10)
driver.set_page_load_timeout(10)
driver.set_script_timeout(10)
driver.maximize_window()
return driver
def main():
path = './screenshot/'
driver = open_driver()
f = open('./url_list.txt', 'r')
try:
url_list = f.readlines()
for url in url_list:
driver.get(url)
filename = path + driver.title + '.png'
driver.save_screenshot(filename)
except Exception as e:
log.error('selenium screenshot error.')
finally:
f.close()
driver.quit()
if __name__ == '__main__':
main()https://www.naver.com/
https://www.google.com/
https://www.daum.net/
url_list.txt 파일에는 위와 같이 네이버, 구글, 다음의 주소가 적혀있고 해당 파일을 한 줄씩 읽어 selenium을 이용하여 접속한 뒤 사이트의 title을 파일명으로 하는 스크린샷을 저장하도록 하였다.


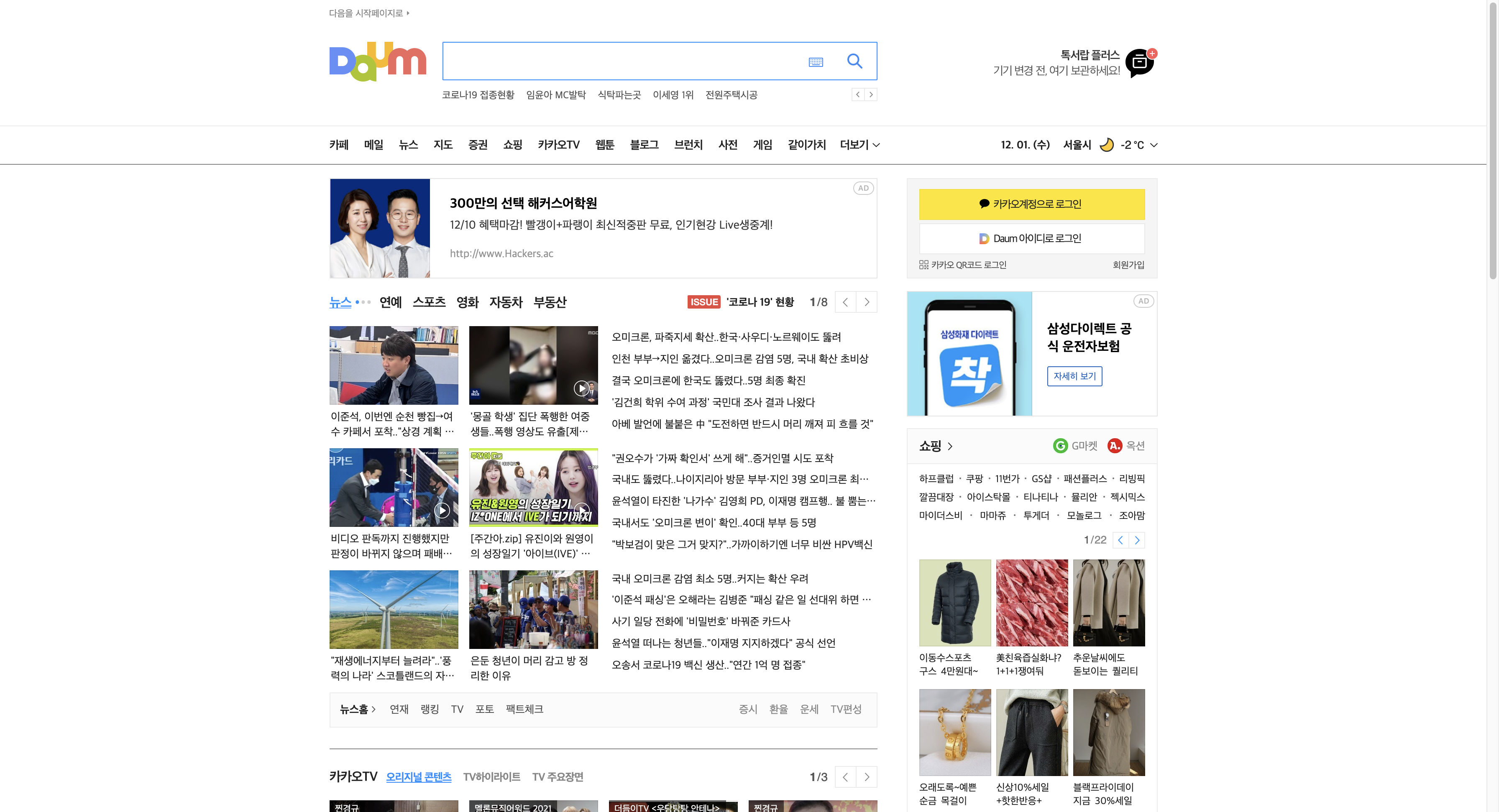
매우 간단하게 만들 수 있었고, 결과적으로 쓸모가 없었다.
만들면서 selenium 스크린샷 찍는 법을 알았다는 것에 만족해야지...
'Python' 카테고리의 다른 글
| [Python] 폴더가 존재하지 않을 경우에만 폴더 만들기 (0) | 2022.03.31 |
|---|---|
| [Python] __init__.py 뭐하는 파일인가요? (0) | 2022.01.10 |
| [Python] Python 반복문 개선하기 (0) | 2021.11.16 |
| [Python] Python 코드 실행시간 측정하기 (0) | 2021.11.12 |
| [Selenium] Selenium Expected Condition 정리 (2) | 2021.10.30 |