지난 repmgr을 이용한 이중화 구성 포스팅에서 primary에서 테이블을 생성하고 데이터를 기록하면 standby에서도 해당 테이블을 조회할 수 있는 것을 확인하였다.
하지만 이렇게까지만 설정한다면 pglogical과 별반 다를 것이 없다.
이번에는 repmgr이 제공하는 auto failover 기능에 대해 알아보기로 하였다.
1. repmgr.conf 설정하기
auto failover를 사용하기 위해서는 repmgr.conf를 수정한 뒤 repmgrd를 시작하면 된다.
vi /etc/repmgr/14/repmgr.conf
failover='automatic'
promote_command='repmgr standby promote'
follow_command='repmgr standby follow --upstream-node-id=%n'
repmgrd_service_start_command = 'sudo systemctl start repmgr14.service'
repmgrd_service_stop_command = 'sudo systemctl stop repmgr14.service'
log_file='/var/log/repmgr/repmgrd.log'
기본적으로는 위에 작성한 내용만 입력해준 뒤 repmgrd를 이용하면 auto failover를 처리할 수 있다.
failover를 'automatic'으로 설정하고 promote 커맨드와 follow 커맨드만 지정해주면 auto failover를 이용할 수 있는데, 사실 테스트 환경과 같이 n중화가 아닌 서버 2개로 이중화하는 경우에는 follow 커맨드는 굳이 필요하지 않다.
follow 커맨드는 여러 개의 standby가 있을 때 primary로 승격된 서버를 다른 standby가 따르도록 하는 것인데 , 현 상황에서는 primary가 죽으면 남은 하나가 primary로 작동하기 때문에 중요하지 않다.
스크린샷을 보면 reconnect_attempts와 reconnect_interval을 3과 5로 지정해 주었는데, 이는 업스트림 노드에 5초 간격으로 3회 연결했을 때 즉, 15초가 지났을 때 failover를 수행하는 설정이다.
기본적으로 reconnect_attempts는 6회, reconnect_interval은 10초로 설정되어 약 1분 정도 업스트림 노드가 응답이 없을 경우 failover가 수행된다.
또 다른 설정으로는 monitor_interval_secs와 connection_check_type가 있다.
monitor_interval_secs는 업스트림 노드의 가용성을 확인하는 간격을 지정하는 설정이다. 기본으로 2초로 설정되어 있어 굳이 변경할 필요성이 없어 건들지 않았다.
connection_check_type은 업스트림 노드의 가용성을 확인하는 방법을 지정하는 설정이다. ping, connection, query 중 하나를 설정할 수 있다. 기본적으로는 ping으로 설정되어 있다.
connection은 업스트림 노드에 새로운 연결을 시도하여 가용성을 결정하고, query는 업스트림 노드에 SELECT 1 쿼리를 날려 가용성을 결정하는 방식이다.
vi /etc/logrotate.d/repmgr
/var/log/repmgr/repmgrd.log {
missingok
compress
rotate 52
maxsize 100M
weekly
create 0600 postgres postgres
postrotate
/usr/bin/killall -HUP repmgrd
endscript
}
위 설정에서 /var/log/repmgr/repmgrd.log에 repmgr에 대한 로그를 기록하도록 설정하였다.
이 로그 파일이 계속해서 쌓이게 되면 시스템에 문제를 일으킬 수 있으니 logrotate를 이용하여 제한을 걸어준다.
위에 있는 logrotate는 repmgr 공식 문서에서 작성된 내용이고, 원하는 주기가 있다면 변경해 주면 된다.
systemctl start repmgr14.service
이제 systemctl을 사용하여 repmgrd를 실행시켜주면 auto failover는 정상적으로 수행될 것이다.
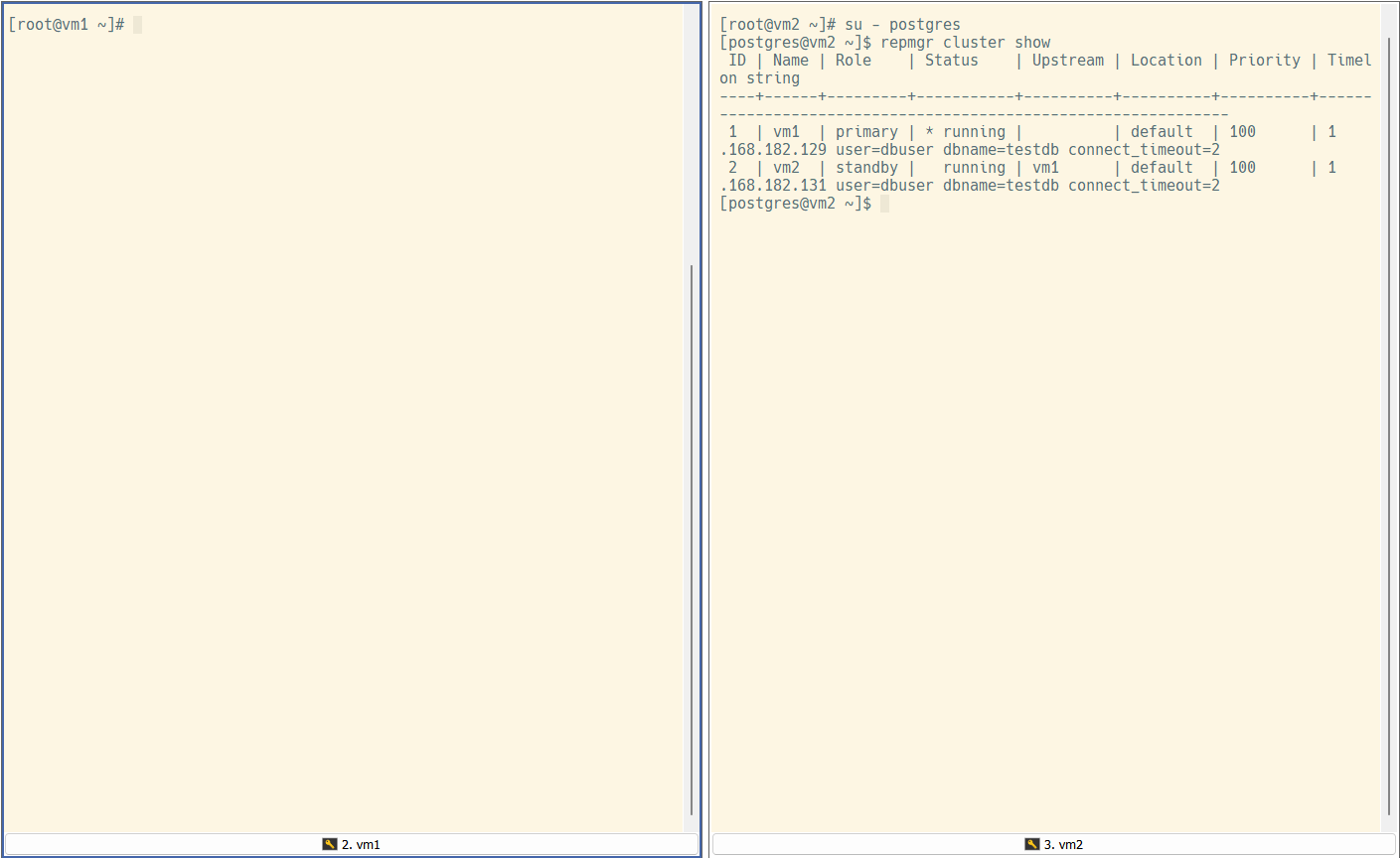
현재 vm1 서버가 primary 상태로 등록되어 있으니 해당 서버를 shutdown 한 뒤 repmgr cluster show를 15초 뒤에 사용하여 정상적으로 failover가 이루어졌는지 확인하면 된다.
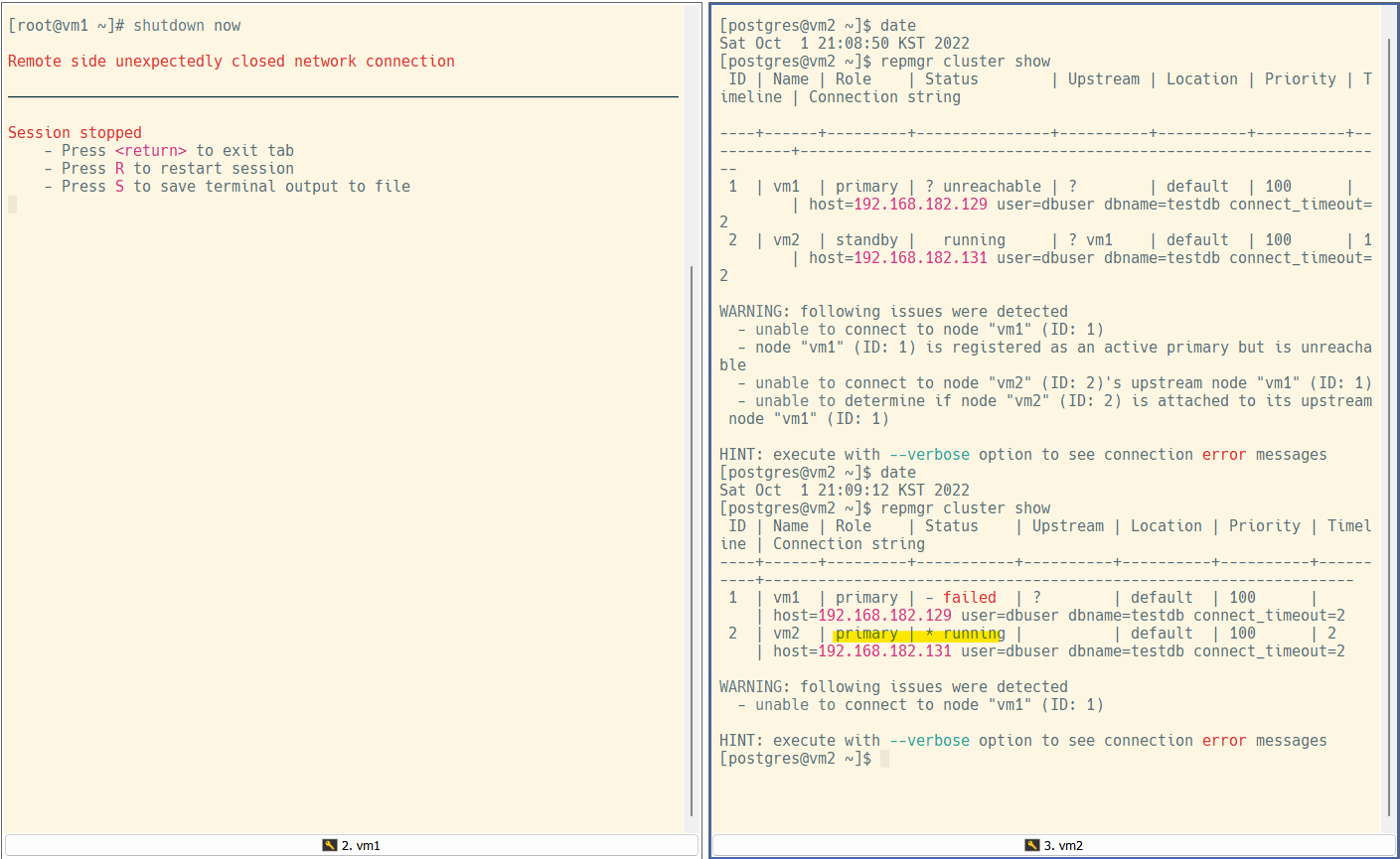
vm1 서버의 전원을 끄고 repmgr cluster show로 클러스터 상태를 확인하였을 때는 vm2는 아직 standby 상태이고 업스트림 노드에 연결할 수 없다는 에러가 발생하고 있었다.
시간이 흐른 뒤 vm2가 primary가 된 것을 확인할 수 있다.
여기서 vm1을 재부팅하게 되면 어떻게 될까?

...
vm1은 자신이 primary인데 vm2가 standby이지만 primary로 동작하고 있다고 표시된다.
vm2는 vm1이 실행 중이지만 노드 레코드가 비활성화된 상태라고 표시된다.
문제가 발생한 것이다.
2. auto failover 후 이전 primary를 standby로 등록하기
위에서 발생한 문제를 해결하기 위해서 어떻게 해야 할까...?
별 수 없다. 이전 primary 서버에서 현재 primary 서버 데이터를 복제한 뒤 standby로 재등록해줘야 한다.
sudo systemctl stop postgresql-14.service
repmgr -h {현재 primary IP} -U {유저명} -d {DB명} standby clone --force
sudo systemctl start postgresql-14.service
repmgr standby register -F
이전 primary 서버에서 위 과정을 수동으로 해주어야 다시 primary-standby 상태가 된다.
3. auto failover 후 이전 primary를 standby로 등록 자동화 하기
포스팅을 작성한 후 repmgr.conf를 보다가 plsh를 이용하지 않아도 되는 방법을 찾았다.
plsh 이용을 원하지 않을 경우 3번 항목에서 스크립트 작성 부분과 패스워드 없이 SSH 접속 부분만 적용 후, 4번 항목으로 넘어가면 된다.
plsh를 이용하지 않을 경우 plsh 설치와 트리거 등록 부분은 그냥 넘어간다.
auto failover 후 이전 primary를 standby로 수동으로 등록해 주는 것은 내가 원한 auto failover가 아니었다. 자동으로 standby로 등록시켜주는 것을 바랐다.
https://www.smallcase.com/blog/repmgr-with-postgres11-failover-and-recovery/
Failover & Recovery with Repmgr in PostgreSQL 11
Configuring replication for databases is the best strategy towards achieving high availability. PostgreSQL streaming replication using Repmgr can satisfy this requirement and PostgreSQL being our key database in Smallcase analytics, it's important to keep
www.smallcase.com
방법을 찾던 중 위 글을 보게 되었다.
PostgreSQL 함수에서 쉘 스크립트를 수행할 수 있게 해주는 plsh 확장을 이용하여 자동화하는 방법을 제시하고 있었다.
cd /usr/pgsql-14/share/extension
git clone https://github.com/petere/plsh.git
cd plsh
make PG_CONFIG=/usr/pgsql-14/bin/pg_config
make install PG_CONFIG=/usr/pgsql-14/bin/pg_config
plsh 확장을 git에서 받아온 후 make로 설치해 준다.
만약 make 과정에서 에러가 발생하면서 진행되지 않을 경우
dnf install postgresql14-devel -y로 패키지를 설치한 뒤 다시 make를 진행하면 문제없이 진행될 것이다.
위 과정은 primary와 standby, 양 서버 모두에서 진행해주는 과정이었다.
아래부터는 현재 primary로 등록된 서버에서만 진행한다.
우선 primary에서 psql을 이용하여 DB에 접속 후
CREATE EXTENSION plsh ;
를 이용하여 데이터베이스에 plsh 확장을 활성화시켜준다.
CREATE FUNCTION failover_promote() RETURNS trigger AS $$
#!/bin/sh
/bin/bash /var/lib/pgsql/failover_promote.sh $1 $2
$$
LANGUAGE plsh;
CREATE TRIGGER failover
AFTER INSERT
ON repmgr.events
FOR EACH ROW
EXECUTE PROCEDURE failover_promote();
그 뒤 function과 trigger를 생성해 준다.
repmgr.events에 값이 insert 될 때 실행되는 함수로, event가 'standby_promote' 일 경우 이전 primary 서버로 접속하여 standby register를 수행하는 쉘 스크립트가 호출되게 된다.
이제 다시 양 쪽 서버에서 모두 작업을 해주어야 한다.
위에서 호출하게 되는 쉘 스크립트를 생성해 주어야 한다.
vi /var/lib/pgsql/failover_promote.sh
로 편집기를 열어주고 쉘 스크립트는 아래와 같이 작성한다.
#!/bin/bash
up_id=$1
name=$2
if [ $name == 'standby_promote' ]; then
declare -A servers
if [ $up_id == 1 ] ; then
down_id=2
else
down_id=1
fi
servers[2]="{repmgr에 등록된 2번 노드 IP}"
servers[1]="{repmgr에 등록된 1번 노드 IP}"
while [[ `(ssh -o ConnectTimeout=5 ${servers[$down_id]} echo ok 2>&1)` != 'ok' ]]
do
sleep 2
echo Failed node ${servers[$down_id]} is not reachable >> /var/log/repmgr/repmgrd.log
done
ssh -T ${servers[$down_id]} << EOF
sleep 5
sudo systemctl stop postgresql-14.service && sleep 10
rm -rf /var/lib/pgsql/14/data
repmgr -h ${servers[$up_id]} -d testdb -U dbuser standby clone --force &&
sudo systemctl start postgresql-14.service && sleep 2
repmgr standby register -F
EOF
echo ${servers[$up_id]}
fi
쉘 스크립트를 모두 작성하였으면, 이제 실행 가능 권한을 주어야 한다.
chmod +x /var/lib/pgsql/failover_promote.sh
이제 마지막으로 양 서버의 postgres 계정 간 ssh 접속 시 패스워드 없이 접속이 가능하도록 해주어야 한다.
이건 ssh-keygen으로 키를 생성 후 키 인증으로 ssh 접속이 가능하도록 해주면 된다.
su - postgres
ssh-keygen -t rsa
ssh-copy-id {상대서버 IP}
그 후 ssh 접속을 시도하여 패스워드 인증 절차 없이 ssh 접속이 되는지 확인해 준다.

간혹 key를 넘겨주어도 패스워드를 물어보는 경우가 있는데 이때에는
restorecon -R -v ~/.ssh를 한 번 해주면 패스워드 인증 절차 없이 ssh 연결이 가능해진다.
이제 auto failover 후 이전 primary가 standby로 자동으로 등록되는지 테스트해본다.

현재 vm1이 primary로 등록되어있기 때문에 vm1의 전원을 종료시킨다.

전원 종료 후 vm2가 primary로 승격된 것을 확인할 수 있다.
이제 vm1의 전원을 다시 켜보고 repmgr cluster show로 클러스터 상태를 조회해 본다.

vm1이 standby로 등록되어 있는 것을 확인할 수 있다.

다시 반대로 테스트하여도 정상적으로 auto failover가 이루어지는 것을 확인할 수 있다.
4. plsh를 이용하지 않고 auto failover 후 이전 primary를 standby로 등록 자동화 하기
repmgr.conf를 읽어보던 중 plsh 없이 스크립트를 실행할 수 있다는 것을 알게 되었다.
친절하게 주석으로 설명해주었는데, 쉘 스크립트를 잘 모르는 나는 그냥 넘어가 버렸었다.
vi /etc/repmgr/14/repmgr.conf
event_notification_command='/var/lib/pgsql/failover_promote.sh %n %e'
event_notifications='standby_promote'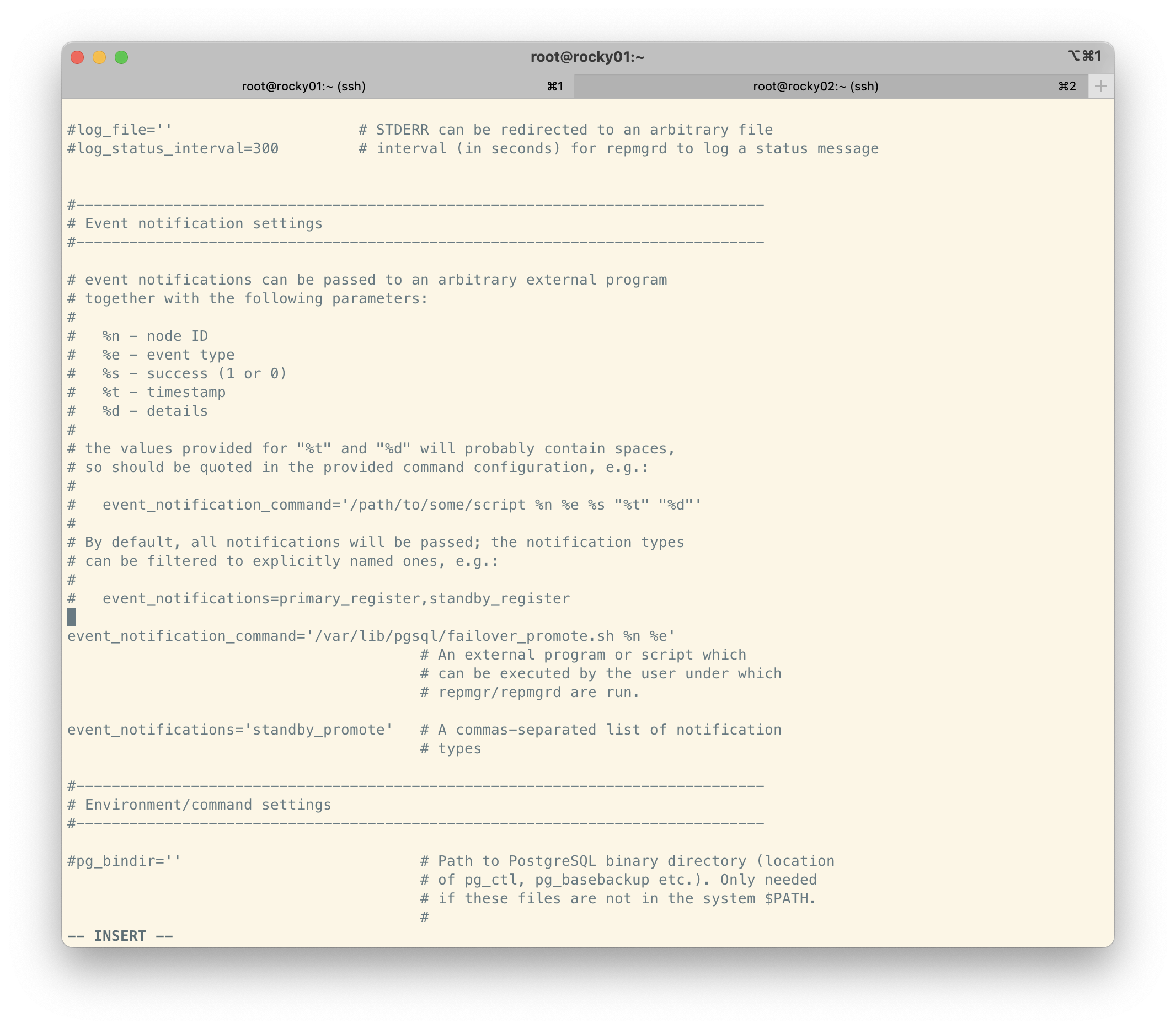
정말 간단하게 트리거를 생성할 필요 없이, event_notifications에 'standby_promote'를 설정하고, evnet_notification_command에 스크립트만 적어주면 된다.
event_notifications에 작성한 이벤트가 발생할 때 event_notification_command에 작성한 스크립트를 실행해주는 설정이었다.
스크립트 뒤에는 %n, %e, %s, %t, %d를 적어 파라미터를 전달할 수 있는데,
%n은 노드의 ID, %e는 발생한 이벤트 타입, %s는 성공 여부, %t는 타임스탬프, %d는 상세 설명을 전달한다.
event_notifications는 쉼표로 구분하여 여러 개의 이벤트 타입을 작성할 수 있다.
event_notifications='primary_register,standby_register,witness_register'
위와 같은 형식으로 여러 이벤트를 등록하고 스크립트 호출 시 %e로 이벤트 타입을 전달하여 쉘 스크립트에서 이벤트에 따른 행위를 작성해 주면 된다.
아래의 이벤트들은 모두 event_notifications로 등록할 수 있다.

'DB' 카테고리의 다른 글
| [PostgreSQL] repmgr을 이용한 DB 이중화 구성하기_3, VIP (1) | 2022.10.03 |
|---|---|
| [PostgreSQL] repmgr을 이용한 DB 이중화 구성하기_1 (0) | 2022.10.01 |
| [PostgreSQL] pglogical을 이용한 DB 이중화 구성하기_2, 양방향 이중화를 구성해 보자 (0) | 2022.09.21 |
| [PostgreSQL] pglogical을 이용한 DB 이중화 구성하기 (1) | 2022.09.20 |
| [PostgreSQL] PostgreSQL 12 설치 후 Job for postgresql-12.service failed because the control process exited with error code. 에러 해결하기 (0) | 2022.09.08 |